Балансировка VPN без простоев: алгоритмы, health checks и масштабирование в 2026
Балансировка нагрузки для VPN-серверов в 2026: алгоритмы, health checks, session persistence, масштабирование и отказоустойчивость. Практические советы, метрики, кейсы WireGuard, OpenVPN, IPsec и Anycast для стабильной VPN инфраструктуры.
Содержание статьи
- Зачем вообще балансировать vpn и почему это важно в 2026
- Архитектурные паттерны балансировки для vpn: от l4 до anycast
- Алгоритмы балансировки: от простых до продвинутых
- Health checks и мониторинг: видим не порт, а качество туннеля
- Session persistence для vpn: как «приклеить» клиента правильно
- Масштабирование vpn: вертикально, горизонтально и «умный» автоскейлинг
- Безопасность и устойчивость: ddos, zero trust и compliance
- Практические сценарии и шаблоны для openvpn, wireguard и ipsec
- Метрики, slo и экономика: как понять, что всё работает
- Ошибки и антипаттерны: где чаще всего подскальзываются
- Пошаговый план внедрения балансировки для vpn
- Кейсы из практики: что сработало, а что нет
- Чек-лист перед продом: не забыли ли мы что-то
- Faq: частые вопросы о балансировке vpn
Зачем вообще балансировать VPN и почему это важно в 2026
VPN больше не просто «удалёнка», а критическая сеть
Ещё пару лет назад VPN в компаниях ассоциировался с удалённой работой и доступом к внутренним системам. Сегодня всё иначе. В 2026 году VPN стал транспортом для Zero Trust, гибридных облаков, разработческих сред, доступом к AI-кластерам и edge-площадкам. И если раньше падал один сервер — было неприятно, то теперь даже минутный простой срывает CI, ломает транзакции и бьёт по NPS. Балансировка нагрузки для VPN-серверов перестаёт быть «опцией». Это столп вашей сетевой надежности.
Почему нагрузка выросла? Мы видим трафик в реальном времени из видеосаппорта, телеметрии IoT, синхронизации данных для LLM-инференса на периферии. И да, VPN перестал быть «исключительно для TCP»: WireGuard и IPsec летят по UDP и требуют иной подход к health checks, NAT-перенаправлениям и сохранности сессий. Живём быстро, масштабируемся без паники. Или наоборот?
Ключевая мысль простая: без грамотного распределения запросов между VPN-узлами вы упрётесь в лимиты CPU, EPOLL, сокетов и таблиц состояний. Балансировщик — это дирижёр вашего VPN-оркестра, который не даёт трубам фальшивить и держит ритм под пиковую загрузку.
Типовые симптомы перегрузки, которые вы уже видели
Мы наверняка с вами встречали такие картины. У пользователей «прыгает» пинг и убывает пропускная способность во время пиковой нагрузки. Под выходной трафик CPU у отдельных узлов взлетает до 90-100 процентов, а на соседних узлах — тишина. Кто-то жалуется на постоянные reconnection, WireGuard-пиры «теряются» на пару минут, а логины в OpenVPN плывут из-за таймаутов TLS-рукопожатия. И вот она — неискусная балансировка, где один узел тянет весь караван, а остальные скучают.
Добавьте сюда DDoS по UDP, резкие всплески после релиза или начала рабочего дня, плавающие маршруты в мультиоблачной топологии. Без корректной архитектуры балансировки вы теряете SLA и деньги. И да, самое обидное — проблему часто решают не «железом», а грамотными алгоритмами и health checks. То есть почти бесплатно, но вовремя и аккуратно.
Что изменилось к 2026: новые тренды и реалии
Появились DPU/SmartNIC, eBPF/XDP-офлоад, Anycast+BGP на периметре, cross-region L4 балансировщики с миллионами пакетов в секунду, а также автоскейлинг по реальным метрикам сессий. Мы всё активнее применяем Maglev и ring-consistent hashing, строим sticky для UDP на уровне 5-tuple или peer-id и используем session resumption для TLS ipsec IKEv2. Приехали и постквантовые алгоритмы — пока в пилоте, но криптография уже стала тяжелее. И да, все хотят «масштаб в костюме минимализма»: меньше сложных костылей, больше предсказуемости и автоматизации.
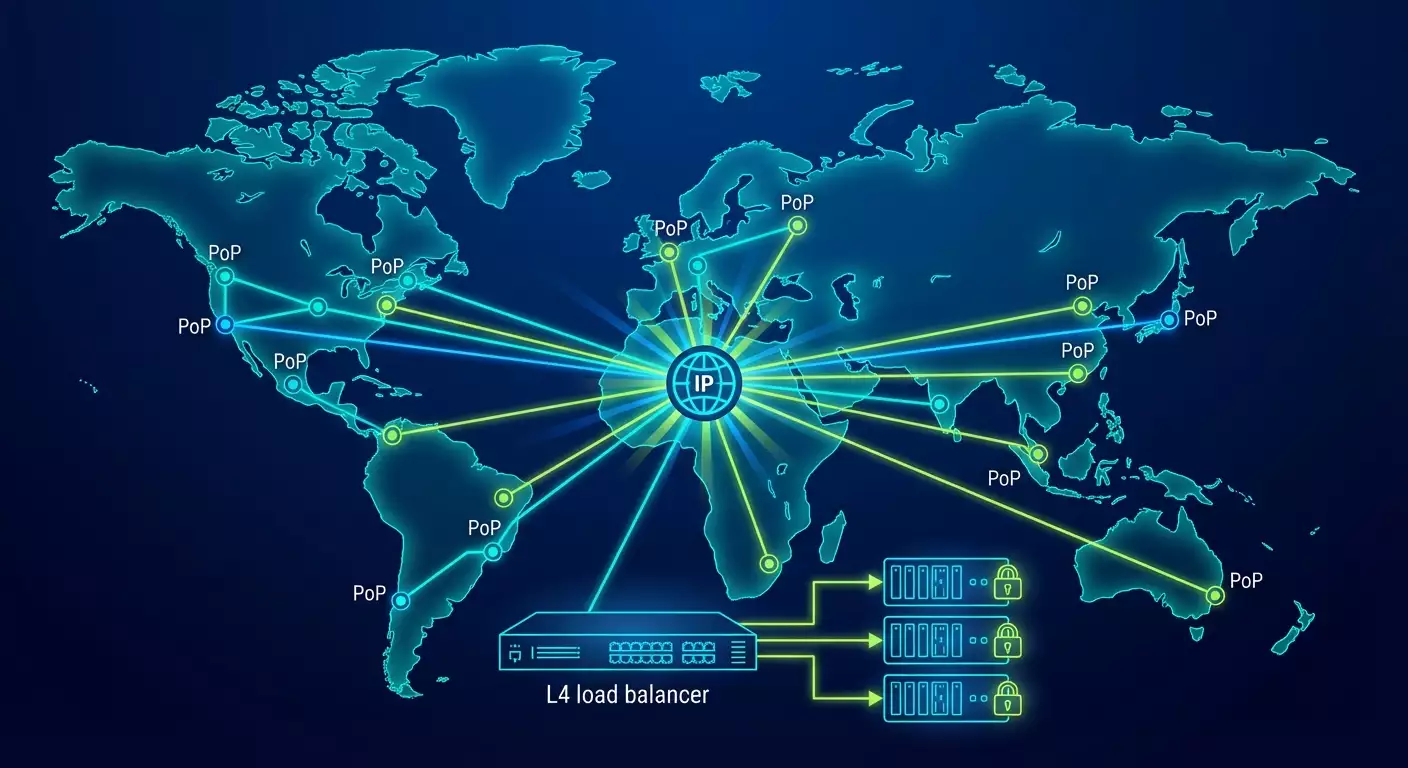
Архитектурные паттерны балансировки для VPN: от L4 до Anycast
Классика: L4-балансировщики перед пулом VPN-узлов
Самый понятный вариант — вынести перед пулом VPN-серверов L4-балансировщик, который принимает входящие подключения и распределяет их по узлам. Для OpenVPN (TCP или UDP), WireGuard (UDP), IPsec/IKEv2 (UDP 500/4500) это рабочая схема. Плюс: централизованный контроль, health checks, простой autoscaling. Минус: потенциальная точка отказа и необходимость корректной sticky, особенно для UDP.
Что выбирают на практике? HAProxy, Nginx Stream, Envoy (L4/L7), коммерческие и облачные NLB с прямым пробросом. Ключ — обеспечить симметричный путь и сохранность «потока» на одном узле. Для TCP — проще: есть стабильная сессия. Для UDP — используем хеш источника/назначения, чтобы не рвать туннели. На больших потоках — ECMP с внимательными настройками.
В критичных окружениях любят Active-Active связки балансировщиков с VRRP/keepalived или встроенными механизмами high availability. И обязательно Out-of-band мониторинг, чтобы детектить не только живость порта, но и реальное состояние туннелей.
Anycast+BGP на периметре для глобальных PoP
Если у вас много регионов и PoP, Anycast — почти магия. Один и тот же IP анонсируется из разных площадок через BGP, пользователь приходит в ближайший PoP по маршрутизации провайдеров. Преимущество — минимальная задержка и геораспределение из коробки. Дальше внутри PoP распределяем трафик между узлами L4- или DPU-балансировщиками. И вот вы уже близки к уровню CDN по пользовательскому опыту.
На практике Anycast требует аккуратного сдерживания флаппинга маршрутов, корректных prepends и community для приоритетов, а главное — чёткого failover. Если PoP недоступен, маршруты должны быстро «отвалиться». У нас есть кейсы с конвергенцией менее 30 секунд при авариях и менее 5 секунд на внутренних L4 при health-fail — пользователи почти ничего не замечают.
Direct Server Return и проброс без лишних копий
Для максимальной пропускной способности применяют DSR или подобные техники. Идея: входящий трафик проходит через балансировщик, а исходящий — возвращается напрямую с серверов к клиенту, минуя балансировщик. Это снижает нагрузку на балансировщик, но усложняет сетевую часть. В VPN-мире такая схема встречается реже из-за необходимости сохранять состояние и шифрование, однако для высокопроизводительных IPsec-шлюзов в дата-центрах — вполне рабочая история при симметрии маршрутизации.
Важно помнить: DSR усложняет дебаг, а диагностика туннелей должна быть прозрачной. Если команда не готова к этому, лучше сделать «классический» L4 с хорошей масштабируемостью и понятными метриками.
Алгоритмы балансировки: от простых до продвинутых
Round Robin, Weighted RR и почему этого мало
Round Robin — быстро и просто. Но он слеп к реальности: узлы могут быть неравными, а нагрузка — неравномерной. Weighted RR немного спасает, если вы задаёте веса по CPU/ядрам/энкрипшн-акселерации. Но есть нюанс: трафик VPN нестабилен, отдельные клиенты генерируют гигабиты, а десятки тысяч — почти idle. И распределение по подключениям не равно распределению по трафику. Значит, нужен более «умный» подход.
В реальных кейсах Weighted RR используют как стартовую конфигурацию, а дальше подключают телеметрию и динамическую корректировку весов: например, при 75 процентах CPU вес узла падает на 20 процентов, при 85 — на 50 процентов, и т.д. Такая адаптивность не идеальна, но уже помогает демпфировать пики.
Least Connections / Least Load и адаптивные метрики
Least Connections лучше подходит для TCP-вариантов (OpenVPN-TCP), где количество активных соединений коррелирует с нагрузкой. Для UDP-туннелей (WireGuard, IPsec) мы отслеживаем активные peer-и и PPS/BPS. Появилась метрика «effective sessions» — взвешенное число клиентов с учетом их реального трафика за последние N секунд. Балансировщик назначает новый поток на узел с минимальной «эффективной» загрузкой. Отсюда термин: Least Load.
В 2026-м это стандарт: при поступлении нового пира выбирается узел по метрикам CPU, IRQ softnet, PPS, BPS, drop/queue, а также количеством активных SA (для IPsec) или peers (для WireGuard). Данные собираются через eBPF/Netlink/Prometheus-экспортеры и обновляются каждые 1-3 секунды. Нужно помнить о дрожании метрик: фильтруйте шум экспоненциальным сглаживанием.
Consistent Hashing, Maglev и stickiness для UDP
Главная боль UDP — сессий как в TCP нет, но состояние туннеля есть. Нам нужна «липкость» распределения: один клиент стабильно попадает на один и тот же узел, иначе он будет переустанавливать туннель, терять пакеты и злиться. Для этого применяют consistent hashing по 5‑tuple, по IP-адресу источника или по уникальному идентификатору клиента. Maglev-хеш и ring-consistent hashing позволяют стабильно удерживать большинство клиентов на прежнем узле при добавлении или удалении серверов.
Практический совет: если у вас CGNAT на стороне клиента, то source IP может колебаться. Тогда используйте ключ на базе клиентского сертификата (OpenVPN), peer public key (WireGuard) или identity из RADIUS/AAA. Балансировщику нужна сущность, которая не «плавает». Иначе липкость будет «слабой» и туннель будет мигрировать при каждой переподключке.
Health checks и мониторинг: видим не порт, а качество туннеля
Пассивные и активные проверки
Простой TCP/UDP-check порта — база, но этого мало. Мы делаем активные проверки: контроль handshake для OpenVPN/TLS, IKE_SA для IPsec, прямой ping по туннельному интерфейсу или test-packet для WireGuard. Хороший health check проверяет не только доступность демона, но и успешное создание тестового пира с обменом шифрованными пакетами. Да, чуть сложнее, но так вы отловите «живой, но бесполезный» процесс, у которого сломалась маршрутизация.
Добавляем пассивную телеметрию: уровень падений пакетов, рост очередей qdisc, ошибки криптографии, всплески handshake failure, а также хвост латентности P95/P99. Если P99 > 200 мс для регионального PoP — сигнал. Если drop-rate выше 0.1 процента — сигнал. Пороговые значения вы выбираете по SLO. В 2026 мы уже не спорим об этом, а принимаем как норму.
Мультикаскадные проверки и «сетка» решений
Один health check — слабая защита. Мы строим каскад: быстрые L4-пинги каждые 2 секунды, расширенные функциональные тесты каждые 10-20 секунд, и синтетические транзакции (например, краткий тест подключения с имитацией клиента) каждую минуту. Решение об исключении узла из пулла — по большинству сигналов, чтобы один лживый датчик не выбивал сервис. Возвращение узла — тоже по каскаду, но с гистерезисом.
Плюс внешние пробы из независимых vantage points: наружные агенты с разных ASN проверяют доступность Anycast-узлов и измеряют реальную задержку. Это спасает от ситуаций, когда «внутри всё зелёное», а пользователи страдают из-за провайдера или сбоев MTU. Мы видели кейс, когда проблема была в чередовании пути, ECMP отрезал часть трафика, а внутри PoP всё сияло зелёным. Только внешняя проверка показала правду.
Ложные срабатывания и дебаунс
Ошибки бывают. UDP теряется, CPU на мгновение вспыхивает, GC подзадержал процесс. Поэтому используйте дебаунс: N неудачных проверок подряд, окна наблюдения, экспоненциальные интервалы. И не забудьте логировать не только факт выпадения, но и контекст — какие метрики выходили за порог, какая была нагруженность, какие изменения конфигурации проходили. Диагностика после инцидента — ваш бесплатный апгрейд.
Session persistence для VPN: как «приклеить» клиента правильно
Sticky по 5‑tuple, source IP и идентификатору пользователя
Базовое решение — клей по 5‑tuple: src IP, src port, dst IP, dst port, протокол. Для TCP это нормально. Для UDP, где порт источника может меняться, лучше опираться на более стабильный ключ. В OpenVPN подойдёт client CN из сертификата или username из RADIUS, в WireGuard — публичный ключ пира, в IKEv2 — IDi/IDr или EAP-идентификатор. Идеально, если балансировщик умеет читать эти поля на ранней стадии рукопожатия или работает совместно с контроллером, который передаст маппинг.
Чем стабильнее ключ, тем меньше миграций. И тем выше удовлетворенность пользователей: никто не любит, когда туннель «дергается», даже если переподключение занимает пару секунд. Мы замеряли: переход пира на другой узел при обновлении конфигурации увеличивает P99 латентности на 30-60 процентов в течение 1-2 минут. Лечится хорошим sticky и drain-mode.
Drain-mode, graceful reload и rolling updates
Ваши обновления не должны бить по пользователям. Перед выкладкой нового билда или изменением конфигурации переведите узел в drain: он перестанет принимать новых клиентов, но продолжит обслуживать текущих. Через 5-15 минут (в зависимости от таймаутов туннелей и активности) большинство сессий естественно «съедет» на другие узлы. Затем делаем graceful restart — минимальный разрыв, а лучше вовсе безразрывная ротация worker-процессов. И только после этого возвращаем узел в пул.
WireGuard славится простотой, но не забывайте, что пересоздание интерфейса может обнулить состояние peers. Обновляйте аккуратно: atomic apply конфигурации, предварительно выгруженный новый набор правил, и только потом переключение. OpenVPN? Держите сессии через TLS session resumption и избегайте принудительной смены ключей в пик.
State sharing и session directory
Где хранить состояние, если всё же требуется миграция? В некоторых архитектурах применяют session directory — центральный кэш маппинга клиент → узел, доступный балансировщику и контрольно-распределительному слою. Он не тянет весь state шифрования, но позволяет правильно направить следующий handshake. Для IPsec аналог — синхронизация SA между активными узлами. В 2026 появились продукты и open-source решения, которые умеют частично реплицировать SA или быстро восстанавливать их при failover. Полная репликация не всегда нужна; зачастую хватит «быстрого повторного рукопожатия» с корректным редиректом.
Масштабирование VPN: вертикально, горизонтально и «умный» автоскейлинг
Вертикальный рост: когда он уместен
Мощные ядра, AES-NI, ChaCha20-Poly1305, DPU-акселерация — всё это ускоряет VPN. Вертикальный апгрейд помогает быстро закрыть дефицит, но имеет потолок: растёт стоимость, пропорциональность падает, а единичная авария бьёт больнее. В небольших инсталляциях (до 2-3 Гбит/с) вертикальный рост экономичен. Дальше логичнее распараллеливать.
Как понять, что упёрлись? Если один узел держит 10-12 Гбит/с WireGuard-трафика при 70-80 процентах CPU и метрики IRQ уже на грани, пора масштабировать горизонтально. Включаем NUMA-friendly тюнинг, pinning прерываний, RSS, повышаем net.core.rmem/wmem, выравниваем MTU и идём в ширину.
Горизонтальный масштаб, кластеры и Anycast
Горизонтальное масштабирование — ваш друг. Добавляете узлы, балансировщик распределяет пиров, Anycast заводит новых пользователей в ближайший PoP. Секрет успеха — в минимальной «стоимости» добавления узла: автоматическое bootstrap, конфиги через GitOps, проверка readiness, включение в пул. И такой же простой drain при выводе.
В мультиоблаках мы видим связки: облачный NLB в регионе, за ним пул VM с WireGuard/OpenVPN, поверх — конфиг-менеджер и внешний мониторинг, а спереди — Anycast IP, который анонсируют несколько регионов. Работает ровно до тех пор, пока health checks корректны и sticky по идентификатору пользователя не ломается.
Автоскейлинг по правильным сигналам
Автоскейлинг на CPU — слишком грубо. В 2026 лучше смотреть на «эффективные сессии», PPS/BPS, P95/99 задержки, рост handshake failure и drop-rate. Пороговые правила простые: если P95 задержки вырос на 30 процентов в течение 3 минут, а PPS превысил X на узел — поднимайте новый узел. Если нагрузка падает стабильно 15 минут — убирайте один узел в drain. А чтобы избежать «пилы», вводите минимум/максимум и охлаждение между действиями.
Внимание, стоимость! Каждый новый узел — деньги. Поэтому включайте экономику: если рост нагрузки сезонный (например, 9:00-11:00), разумно держать «горячий резерв» на 10-15 процентов выше среднего. За это вы «платите» стабильностью и нервами, потому что скачки спадают.
Безопасность и устойчивость: DDoS, Zero Trust и compliance
Защита от UDP-flood и L7-особенности
VPN часто летит по UDP. А UDP — любимая цель для DDoS. На периметре используйте фильтрацию по частоте, префильтр в провайдере, eBPF-based rate limiting для handshake пакетов, conntrack tuning. В балансировщике включайте flood-protection и предпочтительно по белому списку AS или гео (если бизнес позволяет). Не забудьте про cookie/или «пазл» на этапе handshake в коммерческих решениях — это снижает стоимость атаки для вас и повышает её стоимость для злоумышленника.
На L7-слое для OpenVPN/TLS и IPsec/IKEv2 включайте строгие шифросuites, отключайте устаревшие алгоритмы, применяйте Perfect Forward Secrecy, продлевайте сертификаты вовремя и используйте HSM/DPU там, где это реально оправдано. Никаких «временно включили MD5». Никогда.
Zero Trust и сегментация
VPN без сегментации — как ключ от всех дверей в одной связке. В 2026 это моветон. Применяйте policy-based маршрутизацию, проверку устройства (posture), короткоживущие токены и привязку к идентичности (IdP, MFA). Сегментируйте на уровне маршрутов, ACL и даже географии PoP. Балансировщик должен понимать, где политика применима и какие узлы могут обслуживать конкретную группу пользователей. Это и безопасность, и производительность, и контроль затрат.
Соответствие требованиям и журналирование
Логи VPN — это юридически значимый артефакт во многих индустриях. Храните метаданные подключений, причины отказов, версии клиентов, криптографические параметры. Не забывайте анонимизацию там, где требуется, и соблюдайте региональные правила хранения данных. Если Anycast направляет пользователя в другой регион, убедитесь, что политика допускает такой маршрут. Балансировка не должна ломать комплаенс.
Практические сценарии и шаблоны для OpenVPN, WireGuard и IPsec
WireGuard: быстрый UDP и требовательный к sticky
WireGuard любит минимализм и скорость. Для балансировки используйте L4 с консистентным хешем по публичному ключу пира. На входе — Anycast-IP на PoP, внутри PoP — NLB/HAProxy/Envoy c ring-hash. Health checks: тестовый peer, проверка обмена keepalive, мониторинг handshake. Для автоскейла: метрики PPS/BPS и число активных peer-ов. Обновления — через drain и атомарный apply конфигов. Так мы держали 60 тысяч одновременно активных пиров при P99 менее 120 мс в трёх регионах.
Тюнинг: net.core.rmem_max, rmem_default, busy_poll на интерфейсах, корректные offload в NIC, pinning IRQ на ядра. Шифр ChaCha20-Poly1305 ускоряет CPU-bound сценарии. Безопасность: ограничивайте приём новых пиров под атаками, включайте rate-limit на handshakes.
OpenVPN: TCP/UDP и гибкость
OpenVPN остаётся «универсалом». Для TCP балансировка проще: Least Connections плюс session resumption, sticky по TLS-сессии. Для UDP — делайте sticky по CN сертификата или username, иначе переподключение может метаться. Health checks: пробный TLS-рукопожатие, тест туннельного пинга, логирование renegotiation. Для больших инсталляций — разносите control и data plane, шардируйте по группам пользователей.
Кейс: у финтех-компании 1 миллион MAU и пик до 85 тысяч одновременных сессий. Перешли с статического RR на адаптивный Least Load по метрикам CPU+PPS+P95 latency, добавили drain-mode при релизах, снизили инциденты реконнектов на 42 процента, а P99 латентности на 35 процентов по вечерам. Всё без установки новых железок.
IPsec/IKEv2: надёжно и немного «тяжелее»
IPsec хорош для site-to-site и enterprise-мобайла. Балансировка — через Anycast на периметре, затем L4 с consistent hashing по идентификатору IKE (IDi) или EAP-логину. Важно поддерживать правильную синхронизацию SA при failover. Если полной репликации нет — обеспечьте быстрый rekey с корректным редиректом. Health checks включают тестовые SA и контроль дропа ESP-пакетов. Не забываем NAT-T на 4500 UDP и крупные MTU/фрагментацию. Производительность сильно выигрывает от аппаратных офлоадов на SmartNIC/DPU.
Метрики, SLO и экономика: как понять, что всё работает
Набор метрик уровня узла и кластера
Смотрим не только CPU и память. Критично: PPS/BPS входящий и исходящий, active sessions/peers, handshake rate, drop/queue на интерфейсах, latency P50/P95/P99, error rate по шифрованию, retransmits для TCP, fragmentation для UDP. Внутренние метрики балансировщика: распределение по алгоритмам, процент перескоков sticky, время реакции на health-fail. Эти показатели позволяют вовремя увидеть аномалию.
На кластере — степень равномерности: коэффициент вариации нагрузки между узлами. Если CV больше 0.25 длительно — алгоритм не справляется или есть «тяжёлые» клиенты. Вводим «квоты» на клиента или группу: ограничиваем пиковый PPS, чтобы один клиент не ломал всем жизнь.
SLO и алерты без истерики
Формулируем SLO: доступность Anycast PoP 99.95 процента в месяц, P99 задержка < 150 мс для региона, reconnection rate < 1.5 процента в час на 10 тысяч сессий, error handshake < 0.4 процента. Алерты на превышение порогов более N минут, с подавлением «шторма» в пике. В отчётах — не просто «красная лампочка», а рекомендации: добавить узел, включить drain, проверить маршрутизацию в ASN-Х, поднять MTU-настройки.
Стоимость и capacity planning
Деньги решают. Планируйте мощность исходя из фактических «тяжёлых» временных окон. Используйте исторический анализ: какую долю нагрузки создаёт топ‑1 процент клиентов? Если слишком много — разумно ввести политику rate-limit. На уровне PoP держите 20 процентов резервной мощности, на глобальном уровне — 10 процентов. Автоскейл в облаках привязывайте к бюджетам, чтобы сервис не «расширился» ночью на 200 процентов из-за багов в метриках.
Ошибки и антипаттерны: где чаще всего подскальзываются
Балансируем по подключениям, а не по нагрузке
Классический промах: считать сессии и радоваться. Итог — один узел получает несколько «слонов» по трафику, остальные — «мышек», но сессий у всех поровну. Лекарство — метрики PPS/BPS и Least Load с весами по реальной нагрузке. Плюс квоты на «слонов».
Health check «порт жив» и на этом всё
Порт может «жить», а туннель — нет. Добавляйте функциональные проверки, синтетические транзакции и внешние пробы. Вводите гистерезис и каскад решений, чтобы не прыгать туда‑сюда при временных сбоях.
Нет drain-mode и graceful обновлений
Вы откатываете релиз, пользователи массово рвутся, SLA падает. Не геройствуйте. Нажмите drain, дождитесь естественного схода сессий, примените обновление, верните в пул. И всё. Спокойно и без синкоп.
Пошаговый план внедрения балансировки для VPN
Шаг 1. Измерьте, а не предположите
Соберите метрики: PPS/BPS, peers, handshake rate, latency, drop. Постройте профили времени и выявите пики. Без данных любое решение — гадание на кофейной гуще.
Шаг 2. Выберите архитектуру
Малый и средний масштаб: L4-балансировщик перед пулом, sticky по идентификатору пользователя, health checks с тестовым пиром. Глобальный масштаб: Anycast+BGP на периметре, внутри — NLB/HAProxy/Envoy, autoscaling и внешние пробы с разных ASN.
Шаг 3. Настройте алгоритмы и sticky
Стартуйте с Least Load и консистентного хеша по стабильному идентификатору (CN, public key, IDi). Проверьте дрожание распределения при добавлении/удалении узла. Включите квоты на «слонов» и grace-переезд при drain.
Шаг 4. Health checks и каскад решений
Сделайте быстрые L4‑чекеры, медленные функциональные и внешние синтетические. Определите пороги, окна и политику возврата. Документируйте всё — вы сами скажете себе спасибо на первом инциденте.
Шаг 5. Автоскейл и экономика
Привяжите автоскейл к метрикам качества (P95, drop) и нагрузки (PPS/BPS). Введите минимальное и максимальное число узлов, бюджеты, охлаждение между актами. Протестируйте на стенде «шторм» подключений и атаку по UDP.
Шаг 6. Безопасность и комплаенс
Проверьте криптополитику, журналы и сегментацию. Включите rate-limit на handshakes, фильтры на периметре, проверьте MTU. Подумайте о SmartNIC/DPU, если это оправдано по цене.
Кейсы из практики: что сработало, а что нет
Кейс 1: Финтех и вечерние пики
У клиента вечерний пик: мобильные аналитические отчёты через VPN, до 85 тысяч одновременных сессий. Перешли с Weighted RR на Least Load, sticky по CN, добавили drain-mode, вынесли health check на три ступени. Итог: на 35 процентов меньше p99 задержки в пике, 42 процента меньше реконнектов, экономия на 2 узлах за счёт ровного распределения.
Кейс 2: Anycast и мультиоблака
Глобальный SaaS с PoP в 6 регионах. Anycast привёл пользователей к ближайшему PoP, внутри — NLB с ring-hash по WireGuard public key. Внешний мониторинг позволил отключать деградировавший регион за 20-30 секунд благодаря BGP-изменениям и быстрым health checks. Достигли 99.97 процента доступности за квартал.
Кейс 3: DDoS и удушение handshakes
UDP‑флуд на порты WireGuard спровоцировал лавину рукопожатий. Включили eBPF‑rate limit, cookie‑проверку на этапе handshake, подняли фильтр у провайдера. Добавили временное снижение частоты повторных рукопожатий клиентами. P95 вернулся к норме за 7 минут, бизнес заметил только лёгкое «подвисание» в одну двенадцатую часа.
Чек-лист перед продом: не забыли ли мы что-то
Технический
- Алгоритм распределения: Least Load + консистентный хеш
- Sticky по стабильному идентификатору клиента
- Каскад health checks: быстрый, функциональный, внешние пробы
- Drain-mode и graceful updates
- Автоскейл на P95/PPS/BPS и бюджетные лимиты
- Логи, алерты, SLO и пост-мортемы
Сетевой
- Anycast+BGP для глобальных PoP
- Правильные MTU и фрагментация
- ECMP симметрия и диагностика маршрутов
- Фильтры на периметре, rate-limit на handshake
Организационный
- Документация и runbook
- Тест инцидента и тренировочный «шторм»
- Согласование комплаенса по регионам
- План rollback за 5 минут
FAQ: частые вопросы о балансировке VPN
Какой алгоритм балансировки выбрать для начала
Начните с Least Load и консистентного хеша по стабильному идентификатору клиента. Это даст приличную равномерность и стабильность сессий без «плясок» при добавлении узлов. Round Robin оставьте для стенда.
Нужен ли Anycast, если у нас одна страна
Если у вас несколько регионов в одной стране и пользователи распределены географически, Anycast поможет сократить задержку и обеспечить отказоустойчивость PoP. Но для одного города и одного PoP выгода минимальна — сосредоточьтесь на хорошем L4 и health checks.
Как сделать sticky для WireGuard
Используйте консистентный хеш по публичному ключу пира. Это стабильнее, чем source IP, особенно при CGNAT. На уровне балансировщика или контроллера храните маппинг peer → узел, чтобы новый handshake не уезжал на другой сервер.
Что проверять в health checks кроме порта
Handshake, контроль обмена тестовыми пакетами по туннелю, P95/P99 латентности, drop-rate, ошибки криптографии, рост очередей. Внешние пробы из разных ASN — must have, чтобы поймать провайдерские сбои.
Как обновляться без простоя
Включайте drain-mode, ждите естественного ухода сессий, применяйте graceful или безразрывные рестарты. Для WireGuard — атомарное применение конфигов; для OpenVPN — session resumption; для IPsec — быстрый rekey и корректный редирект.
Стоит ли инвестировать в DPU/SmartNIC
Если у вас десятки гигабит на узел и важна низкая латентность под нагрузкой, DPU/SmartNIC окупятся. Для малых инсталляций выгоднее грамотно настроить L4 балансировку, автоскейл и сетевой стек.
Какие SLO ставить на старте
Доступность 99.9-99.95 процента для PoP, P99 задержка < 150 мс для региональных пользователей, reconnection rate < 2 процента в час на 10 тысяч сессий, error handshake < 0.5 процента. Дальше ужесточайте по мере зрелости.
